背景
yueduqi-desktop 是一个用 Go + Wails v2 构建的桌面阅读器。后端解析多个书源的网页/API 返回搜索结果和章节内容,前端用 React + TypeScript 渲染界面。
优化前的状态:能跑,但有很多”差不多就行”的妥协——
- HTTP Client 没有连接池复用
- 零缓存,每次请求都打到上游
- 日志路径硬编码
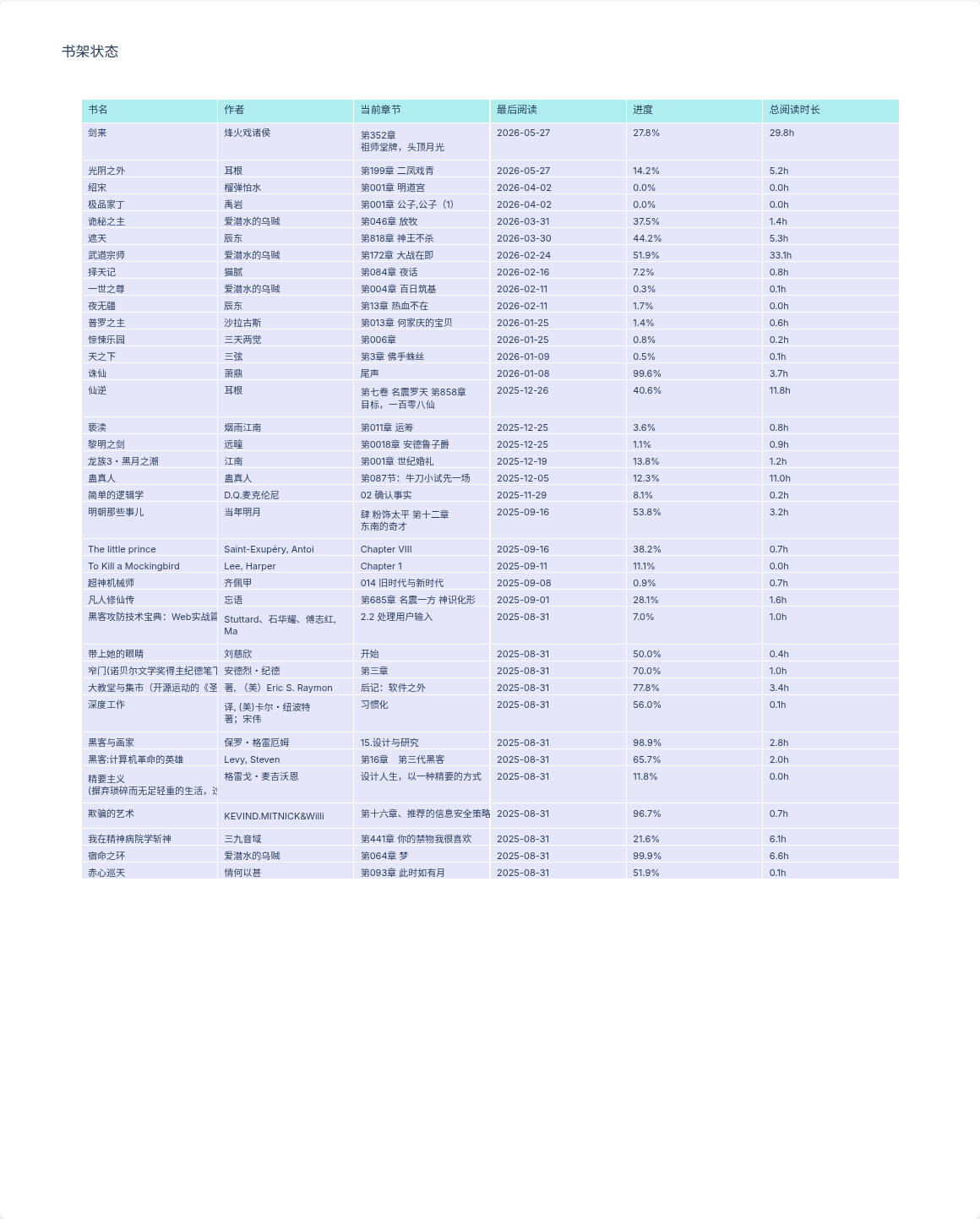
/tmp,无级别控制 - 书架和阅读进度全是 stub(返回假数据)
- Parser 注册靠 switch-case,加新书源要改核心文件
- 错误处理有一堆
_吞错的写法
优化内容
1. 缓存层:cache/cache.go
用 Go 泛型实现了一个带 TTL 的内存缓存:
1 | type Cache[T any] struct { |
热榜(5min TTL)、搜索(3min TTL)、章节列表(10min TTL)各自独立实例。支持运行时开关、统计命中率。
2. 持久化存储:storage/storage.go
用 modernc.org/sqlite(纯 Go,无 CGO)实现了完整的本地数据库:
bookshelf表:书架数据,INSERT OR IGNORE去重reading_progress表:阅读进度,ON CONFLICT DO UPDATEupsertsettings表:用户偏好键值存储memStore兜底:SQLite 不可用时自动切换内存模式
Wails 绑定的 Go 方法(AddToBookshelf、GetBookshelf、UpdateProgress 等)从前端 api.ts 直接调用,不再走 HTTP 层。
3. 配置系统:config/config.go
用 gopkg.in/yaml.v3 加载 ~/.config/yueduqi/config.yaml:
1 | hosts: |
文件不存在时用 Default() 返回合理默认值,不报错。
4. 日志:从 log.Logger 到 log/slog
1 | // 之前 |
结构化日志,支持 debug/info/warn/error 级别,路径从配置读取。
5. Parser 重构
Registry 模式取代 switch-case:
1 | // parser.go |
类型安全: mapItem(map[string]any)替换为具体 struct:
1 | type searchBookItem struct { |
HTTP 连接池:
1 | var httpClient = &http.Client{ |
错误处理修复: 所有 req, _ := http.NewRequestWithContext(...) 改为显式处理 error。
广告过滤合并正则: 18 个独立 regexp.MatchString 合并为单个 adRe,从 O(n×m) 降到 O(n)。
6. 前端改动
api.ts 中书架和进度相关的 stub 全部替换为真实调用:
1 | // 之前 |
遇到的问题
问题 1:Workflow 跑错了项目
一开始用 Claude Code 的 Workflow(多 agent 编排)做优化,但 Workflow 里 agent 的文件搜索先命中了 yueduqi-desktop(字母序靠前),而我真正想优化的是 yueduqi-go。整轮 18 个 agent、66 万 token 全打在了 desktop 上。
解决: 发现后确认 desktop 本身也确实需要优化,就顺势做下去了。教训是给 Workflow 指定目标时要明确绝对路径。
问题 2:Workflow 太重
对于 6 个 Go 文件的小项目,Workflow 的 18 个 agent 每个都要加载完整的系统提示和工具定义(~7K tokens/个),还要各自读一遍代码。66 万 token 里大半是重复的上下文传输。如果是自己直接在主线改,2-3 万 token 就够。
解决: 认识到 Workflow 适合 50+ 文件的大规模审查、跨仓库迁移等场景。小项目应该直接动手改。
问题 3:过度优化 → 删光 → 恢复
Workflow 跑完后我一看 token 消耗,觉得太浪费,冲动之下把所有改动回滚、分支删除。冷静下来才意识到——代码本身是好的,编译通过,质量不错。浪费的是 token,不是代码。
解决: 用 git reflog 找回 commit,用 git stash pop 恢复未提交改动,手动重建了被 rm 掉的 config/ 和 storage/ 目录。
问题 4:超时打架
Workflow 自动生成的代码里,httpClient.Timeout = 15s 是全局上限,但 contentTimeout = 20s 想给内容请求更宽裕的时间。结果 20s 永远用不到——还没到就被 client 层 15s 截胡了。
解决: 把 contentTimeout 降到 15s,和全局超时保持一致。各操作实际生效超时:搜索 8s,章节列表 15s(全局兜底),内容获取 15s。
最终成果
1 | 17 files changed, 853 insertions(+), 48 deletions(-) |
| 模块 | 文件 | 说明 |
|---|---|---|
| 缓存 | cache/cache.go |
泛型 TTL 内存缓存,统计命中率 |
| 配置 | config/config.go |
YAML 加载,默认值优雅降级 |
| 存储 | storage/storage.go |
SQLite + 内存双后端,书架/进度/设置 CRUD |
| 解析 | parser/*.go |
Registry 模式、类型安全、连接池、错误处理 |
| 应用 | app.go |
slog 结构化日志、Store 接口 |
| 入口 | main.go |
XDG 数据目录、SQLite 初始化 |
| 前端 | api.ts 等 |
书架/进度真实 API 调用 |
几点收获
Workflow 要对项目规模有判断。 不是什么任务都值得上多 agent 编排。文件数 < 20 的项目,直接改更快更省。
删代码前先看一眼。 不要被 token 数字吓到——消耗已经发生了,成果是实在的。删掉再恢复只会浪费更多。
超时配置要全局一致。 多层超时(context + client)容易互相截胡。要么都走 context,要么都走 client,别混用。
纯 Go SQLite 真香。
modernc.org/sqlite不需要 CGO,编译出来的二进制照样是单文件。桌面应用持久化的最佳选择。先跑通,再优化。 这次改动的 17 个文件全部编译通过、Wails dev 模式正常运行。没有引入回归是最大的胜利。
项目的完整代码在 GitHub 上。