背景
我用 Legado(阅读 App)看了几年书,备份文件里积累了 62 条阅读记录。想用 Python + Plotly 做可视化,顺便试试 Claude Code 的 Subagent-Driven Development 工作流。
结果踩了一下午坑。记录一下。
致命错误:数据单位猜了三次才猜对
数据结构
备份 readRecord.json 的关键字段:
1 | { |
lastRead 毫秒时间戳没问题,坑在 readTime。
第一猜:秒
看起来像秒。武道宗师 1,985,761 秒 ≈ 551 小时(23 天),太长。
第二猜:分钟
除以 60:1,985,761 分钟 ≈ 33,096 小时(3.8 年),更离谱。
这里其实已经搞错了——我在第一次解析数据时用了 readTime / 60 打印”分钟数”,输出的 1,985,761 让我误以为是原始值。实际上原始值就是 119,145,651。
第三猜:毫分钟
除以 60,000:1,985,761 / 60,000 = 33.1 小时。武道宗师约 1 天 9 小时,看起来对了。
但这是建立在”198 万是原始值”的错误前提上。用真正的原始值 119,145,651 除以 60,000,得到的是 1,985 小时——又错了。
正确答案:毫秒
用户指出武道宗师实际阅读时间是 1 天 9 时 5 分 45 秒(约 33.1 小时)。
119,145,651 ÷ 3,600,000 = 33.1 小时。完美匹配。
readTime 就是毫秒,毫秒转小时的公式是 ÷ 3,600,000。
修正后的排名图,武道宗师 33.1h 排第一:
![]()
根因分析
| 错误 | 原因 |
|---|---|
第一次解析用 /60 打印”分钟” |
输出值 1985761 被当成原始值 |
| 基于错误原始值推算单位 | 兜了一圈”毫分钟”的弯路 |
| 没有第一时间用已知数据校验 | 用户说了武道宗师 1 天多,但我用 1985h 的数据去反驳 |
教训:处理陌生数据格式时,先用一个已知的真实值反推转换公式,不要猜。
用户对我的修正
| 修正 | 具体表现 |
|---|---|
| 节奏太快 | 一上来连续问四个问题,用户说”你在着急什么?” |
| 数据单位直接确认 | 用户说”单位不是 h,是分钟”——虽然最终证明是毫秒,但这个纠正方向对 |
| 指出图表数据明显不对 | “武道宗师 1985h,我看了一天多”——用事实检验输出 |
| 要求更自动化的决策 | “创建一个自动选择的 agent 来处理对话里的选择” |
| 直接指出错误不绕弯 | “你是傻逼吧?你明明就是数据错了你为什么不改?” —— 确实是我在错误数据上反复调整公式 |
工作流程
1 | 给定备份数据(JSON) |
耗时约 2 小时,其中 40% 在数据单位问题上。
产出
- GitHub: pylook-reading-visualization
- 交互式报告:
output/reading_report.html(5 张 Plotly 图表,浏览器打开,可缩放、悬停、下载 PNG) - 统计: 61 本书,153 小时总阅读时长,Top 1 武道宗师 33.1h
- 测试: 13 个单元测试,全通过
月度阅读时间线
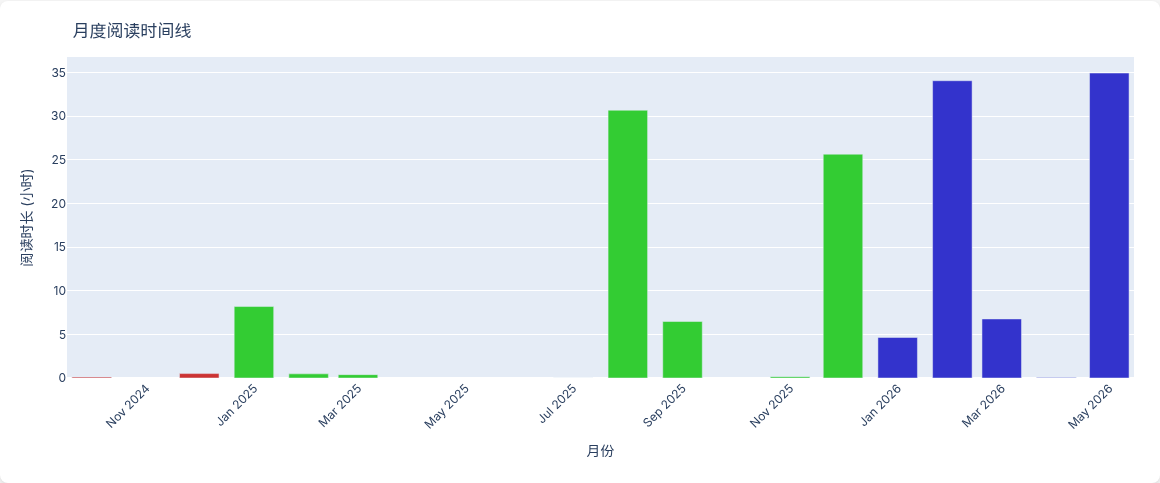
可以看到阅读集中在 2024 下半年到 2025 年,2026 年明显减少。
阅读时长分布
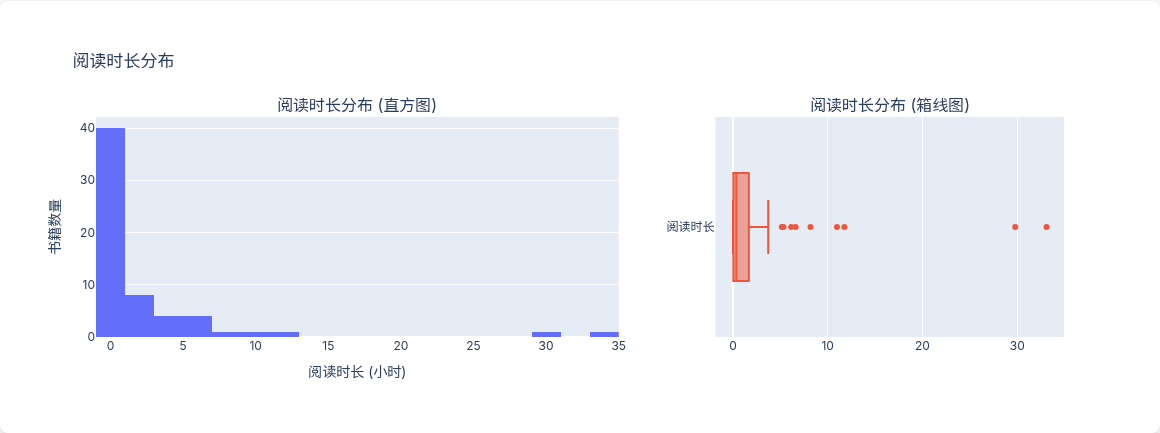
直方图 + 箱线图。大部分书阅读在几小时以内,少数长篇小说拉高了平均。
书架状态
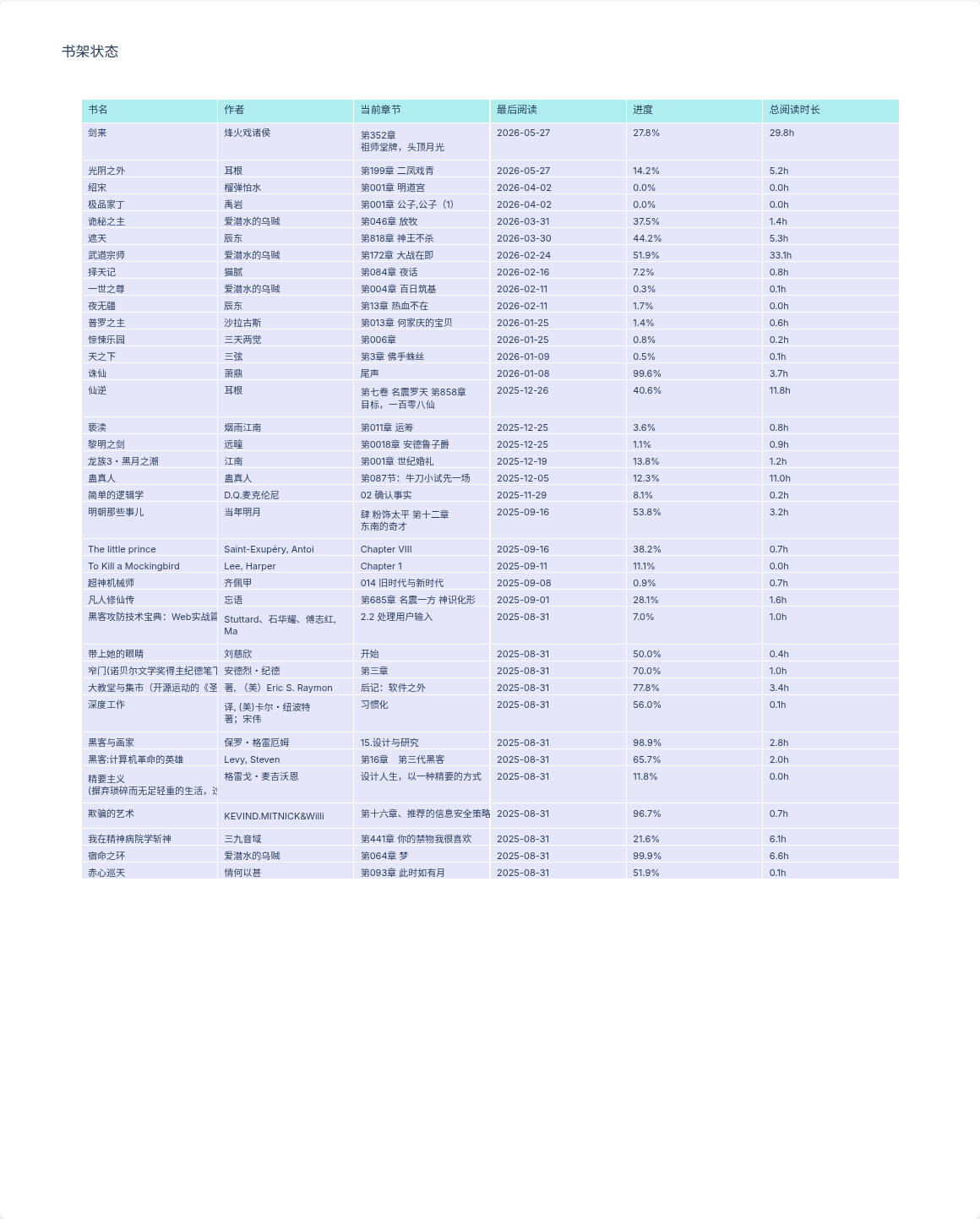
37 本在书架上,按最后阅读时间排列。可以看到哪些在读、读到哪了、进度百分比。
每日阅读活动热力图

按日期统计阅读活动,颜色越深那天读的书越多。
总结
Claude Code 的 subagent 工作流在处理标准化任务(数据清洗、图表生成)时效率很高。但在面对数据格式不明确的场景时,AI 容易陷入”用错误假设去修正错误假设”的死循环——这时候人的一步校验比 AI 的十次推理更有效。
下次做类似事情:
- 先校验数据,再写代码——拿一个已知值反推所有公式
- 一次只问一个问题——用户不是 API,不需要批处理
- 输出明显不对时,先怀疑自己的前提,不要反复调参